【教程】从零开始构建企业级高可用 PostgreSQL 集群

作者序
本文转载自 我的博客站 ,原文地址:【教程】从零开始构建企业级高可用 PostgreSQL 集群
在一切开始之前,请注意以下事项:
- 本文默认你已经完成【教程】从零开始搭建最小高可用 k3s 集群
- 本文所使用的开发环境为
ArchLinux+Fish Shell,由于跨系统指令语法差异,请根据自己的实际情况调整指令格式。 - 本文所使用的对象存储服务为一款兼容 S3 协议的对象存储,请根据自己的实际情况调整配置方式。
- 本文中的指令依赖于各类CLI工具(已在文中标注或是在前置教程中标注,linux系统常见的CLI工具不会在文中标注),由于CLI工具的安装过程较为繁琐且对于各个平台的安装步骤并不一致,此处不再赘述,请参考官方文档的安装教程。
引言
PostgreSQL 是功能最强大的开源关系型数据库(具体优点网上已经被介绍过很多次了,这里不再赘述),这也是笔者用的最多的关系型数据库(没有之一),因此在本人的教程中,所使用的关系型数据库一般以PostgreSQL为主,因此你可以将这篇教程视作Kubernetes相关教程中的一篇非常基础的前置教程
接下来说下这个CloudNativePG(CNPG),它是什么东西呢?简而言之,你可以将它视作是PostgreSQL在Kubernetes的特化版本,大幅简化了PostgreSQL部署与管理的过程,同时也为了满足企业级的要求,它提供了很多的高级特性,包括高可用(HA)、自动化备份、故障演练、自动化扩展等。
本教程将基于 k3s + Longhorn,使用 CloudNativePG 以及通用的 S3 兼容对象存储,从零搭建一套高可用 PostgreSQL 集群,并演示基础的备份、运维操作,最后的最后,我们会手动创造故障,测试数据库的自动化恢复能力
前置条件
在开始部署前,请确保以下前提已经满足:
基础设施
首先,你需要准备一个类似于
【教程】从零开始搭建最小高可用 k3s 集群 中的最小高可用k3s集群
CLI 工具
在开始教程前,你需要准备以下 CLI 工具:
kubectl,用于集群的管理,在上篇教程中,我们已经安装了kubectl,并配置了对远程集群的管理权限(kubeconfig)- 验证指令:
kubectl version --short - 理想输出:显示
Client Version: <client_version>;正常连通时会额外返回Server Version: <server_version>
- 验证指令:
helm, 用于部署 Operator,在上篇教程中,我们已经安装了helm,并配置了对远程集群的管理权限(即kubeconfig)- 验证指令:
helm version - 理想输出:
version.BuildInfo字段中包含Version: <helm_version>、GitCommit: <commit_hash>等信息
- 验证指令:
kubeseal, 用于加密 Kubernetes Secret,请参考官方教程自行安装- 验证指令:
kubeseal --version - 理想输出:输出
kubeseal version: <kubeseal_version>
- 验证指令:
openssl, 用于生成随机密码,这个一般系统自带,如果没有,可以参考官方教程自行安装- 验证指令:
openssl version - 理想输出:输出 OpenSSL 版本信息(如
OpenSSL <openssl_version> ...)
- 验证指令:
第三方基础设施
你需要准备一个 S3 兼容的对象存储服务账号(如 AWS S3、Wasabi、Backblaze B2 或自建 MinIO),并确保能够创建 Bucket 与访问密钥
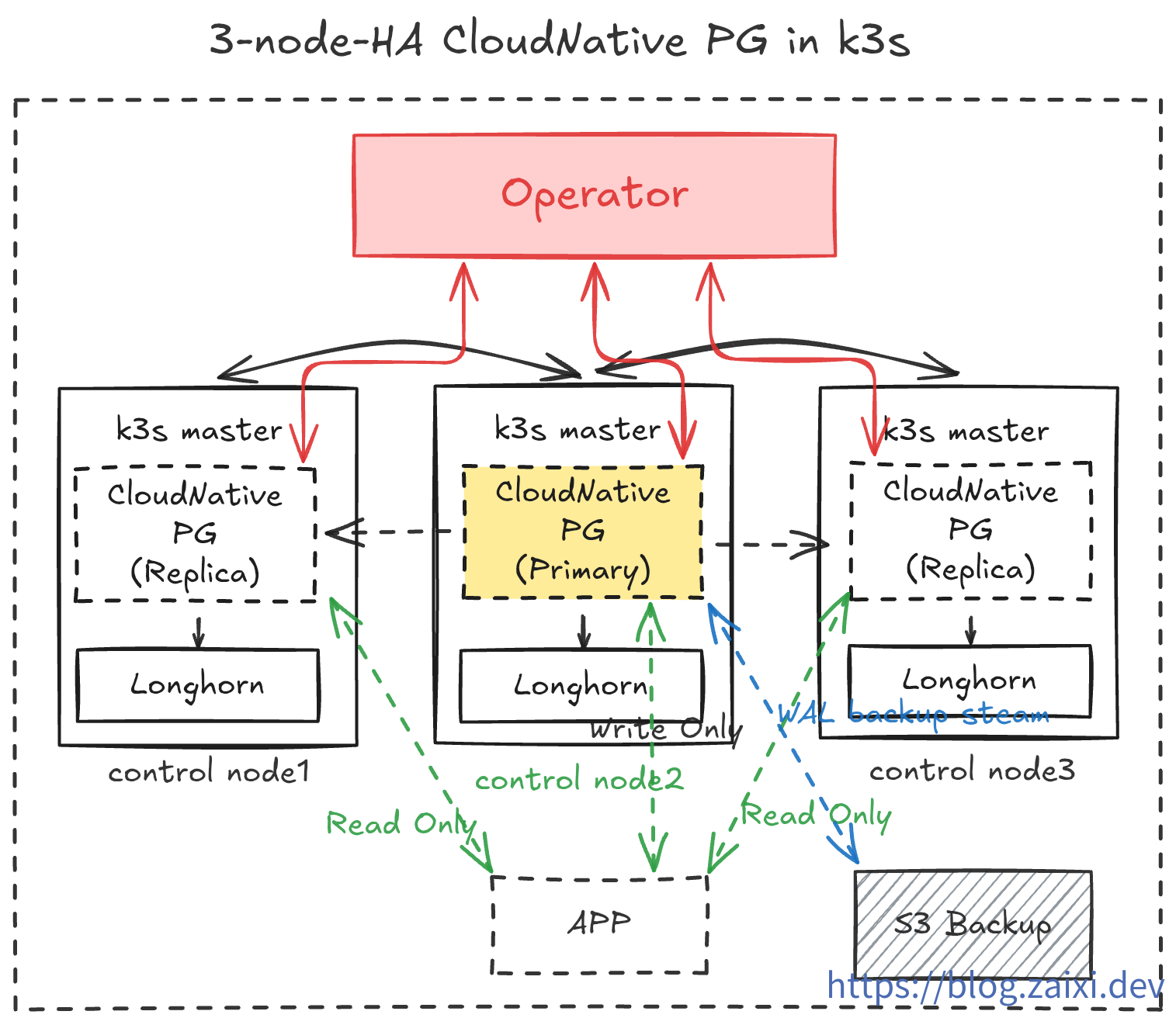
部署架构概览
在本教程中,我们将实现如下操作:
- 在
cnpg-system命名空间中运行 CloudNativePG Operator。 - 在
data-infra命名空间中创建一个 3 副本的 PostgreSQL 集群(1 Primary + 2 Replica)。 - 启用
barman持续备份到对象存储,并为应用暴露一个 ReadWrite Service。 - 借助
cloudflared侧载容器安全地将数据库暴露到公网,用于开发测试。 - 运维演习,测试数据库的滚动更新与插件安装。
- 灾难演习,随机让节点爆炸,观察自动恢复能力。测试在极端环境下用对象存储中的备份数据重建数据库。
- 实现可观察性,通过
Prometheus与Grafana监控数据库状态。
步骤一:安装 CloudNativePG Operator
官方推荐使用 Helm 部署 Operator。首先添加 Helm 仓库并完成安装:
helm repo add cloudnative-pg https://cloudnative-pg.github.io/charts
helm repo update
kubectl create namespace cnpg-system
helm upgrade --install cloudnative-pg cloudnative-pg/cloudnative-pg \
--namespace cnpg-system \
--set controllerManager.resources.requests.cpu=200m \
--set controllerManager.resources.requests.memory=256Mi \
--set controllerManager.resources.limits.cpu=500m \
--set controllerManager.resources.limits.memory=512Mi
结果如图:

安装指令参数解释:
| 参数/片段 | 作用 | 备注 |
|---|---|---|
helm upgrade --install | 若 Release 已存在则升级,否则首次安装 | 保持部署命令幂等 |
cloudnative-pg | Helm Release 的名称 | Helm 用于追踪本次部署 |
cloudnative-pg/cloudnative-pg | Chart 的仓库与名称 | 需提前 helm repo add cloudnative-pg … |
--namespace cnpg-system | 使用的 Kubernetes 命名空间 | Operator 将在该命名空间运行 |
--set controllerManager.resources.requests.cpu=200m | Controller Manager 请求的最低 CPU | 保证调度至少 0.2 核 |
--set controllerManager.resources.requests.memory=256Mi | Controller Manager 请求的最低内存 | 保证调度至少 256Mi |
--set controllerManager.resources.limits.cpu=500m | Controller Manager 的 CPU 上限 | 超过 0.5 核将被限制 |
--set controllerManager.resources.limits.memory=512Mi | Controller Manager 的内存上限 | 超过 512Mi 可能触发 OOM |
如果你希望固定 Chart 或镜像版本,可显式加上
--version <chartVersion>与--set image.tag=<controllerTag>。省略这些参数时,Helm 会使用仓库当前最新稳定版本以及 Chart 默认镜像。
调度机制补充:
controllerManagerPod 由 Kubernetes Scheduler 负责调度,先筛掉不满足资源请求(至少 200m CPU 与 256Mi 内存)的节点,再根据集群当前负载打分,最终选择最合适的节点。如果没有额外的nodeSelector、污点容忍或亲和性设置,它可能落在任意一个满足条件的节点上,但结果是依据算法和节点状态计算出来的,而非完全随机。
如果集群启用了
kube-router、Cilium等网络策略,请确保cnpg-system命名空间内的控制器可以访问 Kubernetes API 与目标命名空间。
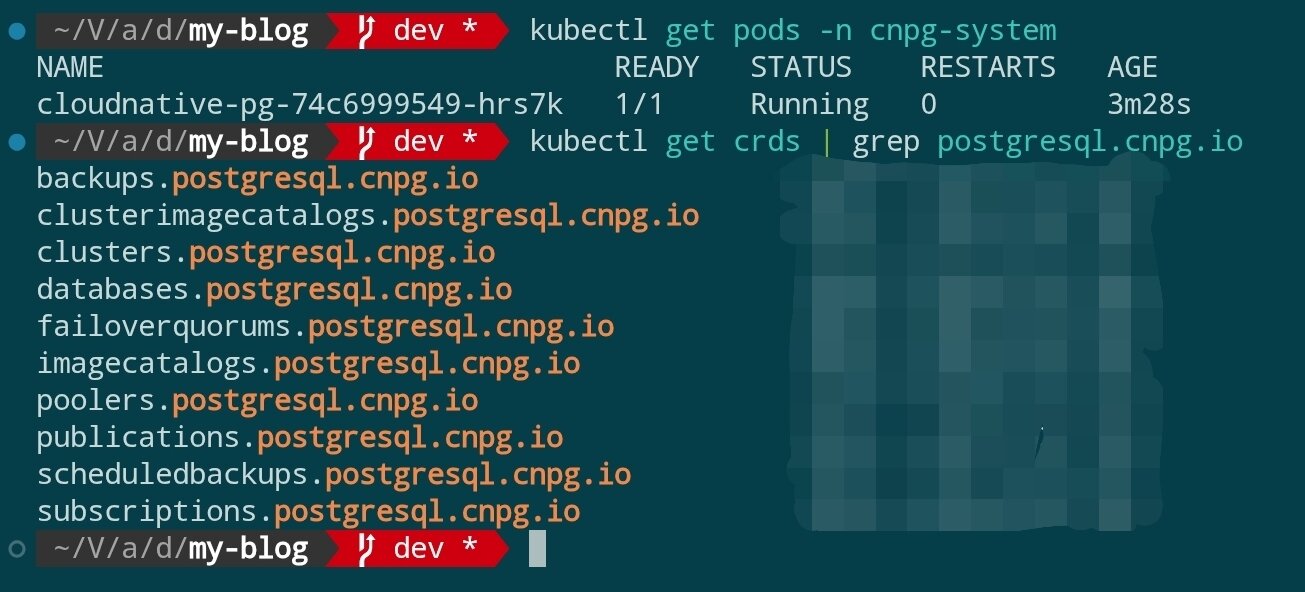
安装完成后,验证 Operator 是否就绪:
kubectl get pods -n cnpg-system
kubectl get crds | grep postgresql.cnpg.io
你应该能看到 cluster.postgresql.cnpg.io 等 CRD 已注册,Operator Pod 处于 Running 状态。
步骤二:准备命名空间与访问凭证
安装 Sealed Secrets
本次教程里,我们需要使用 Sealed Secrets 管理敏感信息。使用 Sealed Secrets 前,需要在集群部署控制器并在本地安装 kubeseal CLI:
常见问题
- Q:为什么要引入 Sealed Secrets?
A:Sealed Secrets 可以把 Kubernetes Secret 加密成 Git 可安全保存的清单。即使存入版本库也不会泄露明文,集群侧的控制器会按权限解封生成真实 Secret,让敏感配置可以使用标准 GitOps 流程同步。
helm repo add sealed-secrets https://bitnami-labs.github.io/sealed-secrets
helm repo update
kubectl create namespace sealed-secrets
helm upgrade --install sealed-secrets sealed-secrets/sealed-secrets \
--namespace sealed-secrets \
--set fullnameOverride=sealed-secrets-controller
上述命令会在
sealed-secrets命名空间运行控制器,名称固定为sealed-secrets-controller,便于后续示例引用。若集群已有现成部署,可跳过此步骤。
下一步,在本地安装 kubeseal 并执行 kubeseal --version 验证版本,请参考官方安装教程。

注意:
kubeseal默认会去kube-system命名空间寻找名为sealed-secrets-controller的服务。如果像示例一样放在sealed-secrets命名空间,且没有指定参数,就会看到error: cannot get sealed secret service: services "sealed-secrets-controller" not found。因此后续命令务必显式传入--controller-namespace sealed-secrets --controller-name sealed-secrets-controller,或根据实际安装位置调整。
常见问题
- Q:为什么运行
kubeseal会提示error: cannot get sealed secret service: services "sealed-secrets-controller" not found?
A:kubeseal会默认去kube-system命名空间寻找同名服务。示例中我们把控制器部署在sealed-secrets命名空间,因此需要加上--controller-namespace sealed-secrets --controller-name sealed-secrets-controller,否则就会找不到。 - Q:既然如此,为什么不直接把服务部署在
kubeseal默认能找到的kube-system命名空间?
A:主要是为了隔离和易维护。kube-system一般由集群底层组件占用,保持该命名空间纯净便于排障。同时独立的sealed-secrets命名空间能集中管理相关资源,在多环境或多租户时也方便做权限控制。工具默认指向kube-system是为了兼容常见安装方式,我们只需按实际部署传参即可。
生成业务 Secret
为数据库层准备单独的命名空间,并使用 Sealed Secrets 管理敏感信息,避免杂项资源混在同一空间:
kubectl create namespace data-infra
生成数据库应用账户的加密 Secret:
Step 1:生成原始 Secret 清单(不会写入集群)
kubectl create secret generic cnpg-app-user \
--namespace data-infra \
--from-literal=username=app_user \
--from-literal=password="$(openssl rand -base64 20)" \
--dry-run=client -o json > cnpg-app-user.secret.json
该命令将用户名和随机密码封装成 Kubernetes Secret 的 JSON 清单并写入 cnpg-app-user.secret.json,同时保持对集群无副作用。生成的文件内容类似:
{
"kind": "Secret",
"apiVersion": "v1",
"metadata": {
"name": "cnpg-app-user",
"namespace": "data-infra"
},
"data": {
"password": "random-password",
"username": "random-username"
}
}
Step 2:使用 kubeseal 加密成 SealedSecret
kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml < cnpg-app-user.secret.json > cnpg-app-user.sealed-secret.yaml
这里手动读取前一步的 JSON 并交给 kubeseal。命名空间和控制器参数确保 CLI 能连接上我们部署的 Sealed Secrets 控制器,--format yaml 则输出可提交到 Git 的 SealedSecret 文件,此处生成的文件内容类似于:
---
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: cnpg-app-user
namespace: data-infra
spec:
encryptedData:
password: random-password(locked)
username: random-username(locked)
template:
metadata:
name: cnpg-app-user
namespace: data-infra
Step 3:将 SealedSecret 应用到集群并删除原始 Secret
kubectl apply -f cnpg-app-user.sealed-secret.yaml
rm cnpg-app-user.secret.json
控制器接收后会自动解封并生成同名的常规 Secret(cnpg-app-user),供后续数据库资源引用。妥善保管好cnpg-app-user.sealed-secret.yaml,以便在后续的CICD流程中使用。
准备 S3 兼容对象存储凭证
- 登录对象存储服务控制台(如 AWS S3、Wasabi、Backblaze B2 或自建 MinIO 集群),新建一个专用的 Bucket,示例命名
cnpg-backup,Region 选择距离 Kubernetes 集群最近的区域。 - 在 Bucket 的访问策略中关闭公共读写,只允许凭证访问;如供应商支持生命周期或版本管理,可根据合规需求提前配置。
- 进入凭证或密钥管理页面,为本教程创建一对 Access Key,至少授予目标 Bucket 的
Object Read与Object Write权限,必要时可限制在特定前缀范围。 - 记录控制台返回的
Access Key ID、Secret Access Key、Region(若适用)以及 S3 Endpoint,例如https://s3.ap-northeast-1.amazonaws.com或供应商提供的自定义域名。部分厂商会注明是否要求 Path Style 访问,请同步记下。 - 将这些信息保存到密码库,并准备好后续写入 Kubernetes Secret 的明文值:
aws_access_key_id、aws_secret_access_key、region(若未固定 Region 可填供应商推荐值),同时确认 CNPG 中将使用的destinationPath(形如s3://my-cnpg-backups/production)。
完成控制台配置后,即可继续使用 Sealed Secrets 管理这组凭证喵。
使用 SealedSecret 配置对象存储凭证
计划启用对象存储备份时,同样使用 Sealed Secrets 生成访问凭证(以 S3 兼容服务为例):
kubectl create secret generic cnpg-backup-s3 \
--namespace data-infra \
--from-literal=aws_access_key_id=AKIA... \
--from-literal=aws_secret_access_key=xxxxxxxxxxxx \
--from-literal=region=ap-northeast-1 \
--dry-run=client -o json \
| kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml > cnpg-backup-s3.sealed-secret.yaml
kubectl apply -f cnpg-backup-s3.sealed-secret.yaml
步骤三:声明 PostgreSQL 集群
CloudNativePG 使用 Cluster 自定义资源来定义数据库栈。下面是一个生产友好的示例(存储类使用上一教程部署好的 Longhorn):
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cnpg-ha
namespace: data-infra
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:16.4
primaryUpdateStrategy: unsupervised
storage:
size: 40Gi
storageClass: longhorn
postgresql:
parameters:
max_connections: "200"
shared_buffers: "512MB"
wal_level: logical
pg_hba:
- hostssl all all 0.0.0.0/0 md5
authentication:
superuser:
secret:
name: cnpg-app-user
replication:
secret:
name: cnpg-app-user
bootstrap:
initdb:
database: appdb
owner: app_user
secret:
name: cnpg-app-user
backup:
barmanObjectStore:
destinationPath: s3://my-cnpg-backups/production
endpointURL: https://s3.ap-northeast-1.amazonaws.com
s3Credentials:
accessKeyId:
name: cnpg-backup-s3
key: aws_access_key_id
secretAccessKey:
name: cnpg-backup-s3
key: aws_secret_access_key
region:
name: cnpg-backup-s3
key: region
retentionPolicy: "14d"
monitoring:
enablePodMonitor: true
保存为 cnpg-ha.yaml 并应用:
kubectl apply -f cnpg-ha.yaml
CNPG 会自动创建 StatefulSet、PVC、服务等资源。等待 Pod 启动完成:
kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha -w
当 Primary 与 Replica 都处于 Running 状态时,数据库集群即部署完成。
步骤四:验证高可用与服务暴露
检查服务与连接信息
kubectl get svc -n data-infra -l cnpg.io/cluster=cnpg-ha
kubectl port-forward svc/cnpg-ha-rw 6432:5432 -n data-infra
psql "postgresql://app_user:$(kubectl get secret cnpg-app-user -n data-infra -o jsonpath='{.data.password}' | base64 -d)@127.0.0.1:6432/appdb"
CNPG 默认会创建 -rw(读写)与 -ro(只读)Service,方便应用分别接入主库与备库。
模拟故障切换
强制删除 Primary Pod 验证自动恢复能力:
kubectl delete pod -n data-infra \
$(kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary -o jsonpath='{.items[0].metadata.name}')
几秒钟内,CNPG 会自动将一个 Replica 提升为 Primary。通过下列命令确认角色变化:
kubectl get pods -n data-infra -L role
kubectl logs -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary --tail=20
步骤五:备份与灾备策略
- 持续备份(PITR):
barmanObjectStore配置将 WAL 持续写入对象存储,可通过kubectl cnpg backup命令触发全量备份。 - 定期演练恢复:在临时命名空间中创建
Backup+ClusterCR,验证从对象存储恢复到指定时间点。 - 监控与告警:开启
monitoring.enablePodMonitor后,可在 Prometheus 中抓取cnpg_pg_replication_lag、cnpg_pg_is_in_recovery等关键指标。 - 资源配额:为
data-infra命名空间配置LimitRange与ResourceQuota,防止数据库实例挤占节点资源。
常见运维操作
- 在线扩容:调整
spec.instances数量即可,CNPG 会自动创建新的 Replica 并同步数据。 - 参数调整:更新
spec.postgresql.parameters,Operator 会触发滚动重启完成配置下发。 - 版本升级:修改
spec.imageName指定新版本镜像,CNPG 会先创建新 Replica,执行switchover后再回收旧主库。 - 逻辑复制:通过
pg_hba与wal_level配置,可以将特定库/表同步到外部数据仓库。
总结与下一步
至此,我们已经在高可用 k3s 集群上部署了一套具备自动故障切换、持续备份、声明式管理能力的 PostgreSQL 集群。下一步可以考虑:
- 引入 Grafana Loki 或 ELK 收集数据库日志,完善观测能力。
- 使用 CloudNativePG Pooler 或 PgBouncer 优化连接池管理。
- 结合 Argo CD/Fleet 等 GitOps 工具,将数据库 CR 纳入持续交付流程,实现配置变更审核与回滚。